
Why?
Everyone is getting a bit excited about Microsoft Fabric, and it’s not even in GA yet. I help run the Birmingham Power BI User Group, and have been asked a few questions about the impact it will have on Power BI Developers. So to answer what is the focus of Fabric, I’m taking a step back and explaining what has changed over the last few years in terms of data delivery. Hopefully it should give some context of what is so great about it.
The Good Old Days (2012)
We’re going to have look on how we used to do Data Warehouses. Most of the projects at that time were still using on-premise servers, in a typically virtualized environment. So we used to have a big old server running SQL Server, 2012 if lucky, 2005 if we were not. In it was a collections of DataMart’s, which if you are not familiar with the term, are reporting databases, that align to a business area/domain.
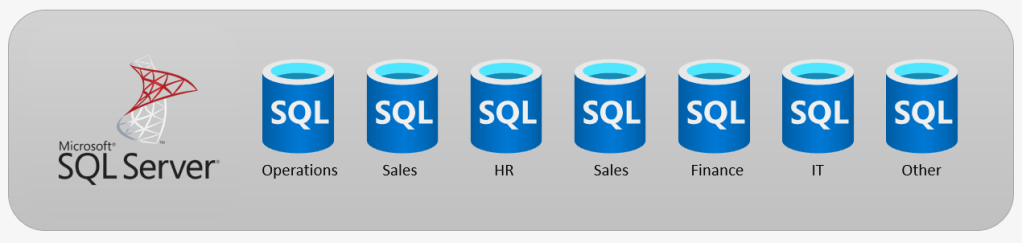
So we have Operations, Sales, HR, Sales (It’s really important), Finance, IT and Other (More sales). Each database contains all the information for that domain. We can, if needed, do cross database queries to mash up data, but normally it remains in it’s domain. However the approach had a few issues.
- Compute and Storage are linked
- It is query restricted and data is locked into the platform
So what does that mean? Well the big old server has a finite amount of computing power and storage. We might be able to add discs, or basically increase the VM CPU, but it is a limited resource at some point. A lot of queries or workloads on it, will affect performance. Data is locked into the database, you will have to export or replicate it to some other place. It is also query restricted in terms of the type of queries you can run. Maybe you want to do some graph or machine learning workloads on it. You’ll need to get the data out into a platform that can handle it.
So it is limited in a number of ways…what happened next?
Along came the cloud
So along came the big data revolution and the cloud, and at the time, cloud services were in their early days. So what happened is we used the cloud to replicate our on premise environments.
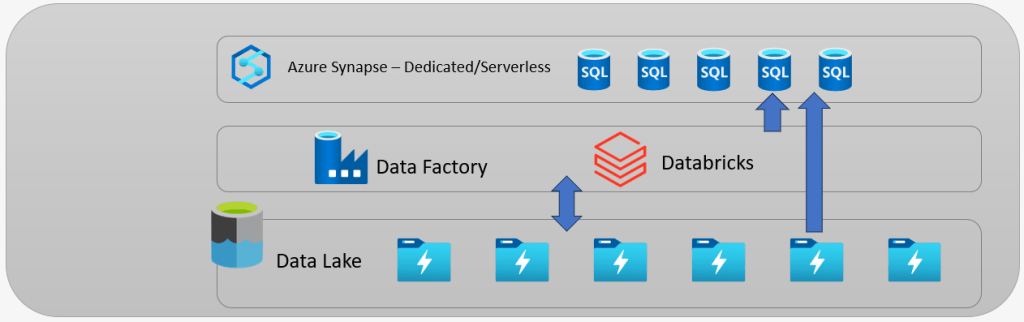
So we had a big data lake, with a big database, which over time moved from, Azure SQL DB then to SQL Data Warehouse and then Synapse.
- Compute and Storage are de-coupled
- It is query unrestricted and data is not locked in
The big change was, compute and storage are de-coupled. Now we have data in the lake, we can put whatever compute resource on top of it. Analytical, Graph, ML, anything we need. It is now accessible and moveable. It is now possible to fire up you own bit of Synapse, and run queries/workloads, or a Databricks cluster, and not have to worry about noisy neighbors running big queries on your server. The freedom was amazing. However in terms of deployment and the new CI/CD approach, it could still be a bit tricky with a big monolith deployment, and teams working on a bit for a particular business domain, would have to worry about it break anything for other teams? Maybe the resource groups now had a lot of services that other teams did not need, like Event Hubs, or Logic Apps. Normally a lot of testing would be needed.
Data Mesh
In 2019, Zhamak Dehghani outlined an approach for a distributed data solution called the data mesh, and she used the idea as ‘Data as a Product’. Teams, now deliver data for use, and in the current idea of ‘Self-service’, users could get access to the data they needed.

This approach now decouples, compute, storage and business domain. It’s a next generation cloud DataMart as I like to think of it. You can open up SQL or Storage endpoints to cross query or access the data, so it is not siloed.
So in terms of Azure, we have a bunch of resource groups, that contain the relevant data lake, compute/query and other bits needed. Maybe Operations has a need for real time streaming, we can just deploy Event Hubs & Stream Analytics to that resource group. We don’t have to worry about big deployments, enabling velocity on each business domain. I do recommend the following blog posts by Paul Andrew Azure & the Data Mesh – Paul Andrew which gives a great overview.
What the F…F…Fabric?
So what does this have to do with Fabric? Well you can view it as ‘Data Mesh as a service’. The Workspace is the mesh. Each workspace can contain what ever resource you need for that domain. It is now a single pane of glass for all the resources. Power BI was an attempt of a single pane of glass, as it gathered together, Power Query, Power Pivot and a Reporting front end. Azure Synapse was also a attempt to bring together SQL Data Warehouse, Spark, Data Factory into a browsers front end. But you had to jump between Azure and Power BI to get stuff done. Now it is all in one place.
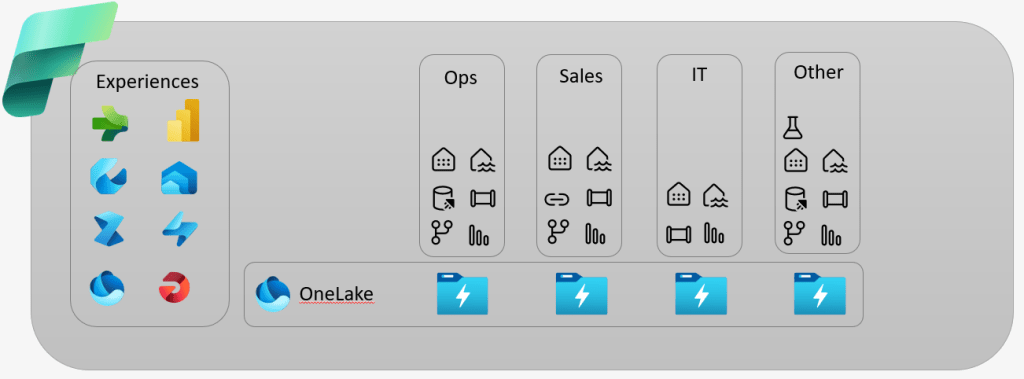
No more worrying about, resource groups, vnets, and all the other things infrastructure. Turn the key, and off we go.
What does this mean for Azure and those data platform services? They will still be needed, Fabric can meet the requirements of a lot of customers. For those others mainly enterprise size, Azure will still be needed. Why? Well you don’t get all the features of Databricks in Spark, Delta Live Tables etc. You can use Azure blobs as a landing area for you data and not OneLake. Why? You can move to data to cold tiers and reduce costs, or have a more secure area for your data. Maybe the serverless Synapse doesn’t quite meet your needs, you can still fire up dedicated. There are all sorts of stuff you may need to do for your data, where Fabric may not meet your demands. It is trying to focus on typical developers and citizen developers, so will it meet the needs of both? Microsoft Fabric is currently in preview and like Power BI seems to be getting a lot of features added, hopefully Microsoft will keep up the pace after GA, but I’m excited about the future of the data platform.
